Indexes
The Indexes view lists all types of indexes (web scrapes, campaigns and banners, knowledge bases, etc.) available in an account. Read more about integrations and indexes on our website.
Scraping Process
The scraper traverses through all specified pages in an index (plus the sitemap for web scrapes) in order to locate and scrape all available text content. Note that pages cannot be scraped if any of the following conditions are present:
- page is not published
- page is not searchable (page has noindex, nofollow tags)
- page is not linked from any page AND not listed in the sitemap
- the site’s
robots.txtfile contains adisallowrule for crawlers
If a page is published and searchable but not linked from anywhere nor included in the sitemap, it can be still be scraped by manually adding the address as an entrypoint URL. Refer to Inclusions, or provide a list of articles (or parent URL for articles under the same topic) to Raffle Support.
Sync Frequency
After the initial scrape, the scraping process is repeated automatically on a regular basis (weekly or daily). All recent changes made on the host index (e.g. updated content) are then reflected in the Raffle scrape after a successful resync.
For websites with sitemap (e.g. website.com/sitemap or website.com/sitemap.xml), Raffle uses the regularly updated <lastMod> tag in order to apply differential scraping, which ensures that only articles with recent changes are re-scraped, resulting in a faster and more optimized syncing process.
Note
For newly launched websites, contact Raffle Support for a quick resync. Otherwise, the scraped data will only be updated after the next successful resync (the next day for daily syncs, or the following weekend for weekly syncs).Scrape Cleaning
By default, articles go through a standard “cleaning” process when first extracted from a connected index. This process involves deduplication checks and css blacklisting in order to exclude specific parts of an article from the scrape (e.g. breadcrumbs, footer, etc.)
For further adjustments, provide a list of pruning requests to Raffle Support.
Sectioning
During the scraping process, the contents of a page are divided into smaller subsections which are used to match with relevant search queries. When a user makes a search, the model tries to find the most relevant sections in the scraped index, and sorts them by relevance. The top (relevant) entries are returned as snippets in the search results list (one section is shown per answer) while the least relevant ones are entered in a different list called Knowledge Gaps.
Whitelisting
Configurations set on a server may prevent Raffle from accessing and scraping the contents of a protected knowledge base, and whitelisting of Raffle IP addresses may be necessary.
Whitelisting is based on the principle of giving access to only trusted entities while blocking all others by default. A whitelist (allowlist) is an exclusive list containing IP addresses of trusted and authorized entities (e.g. users or devices) that can access sensitive data or systems. The process mainly involves assigning these addresses to a user or group of users as unique identifiers, and permitting them access to the target server. This list is set up and maintained by the customer’s IT administrators.
Contact Raffle Support for a list of Raffle IP addresses to be whitelisted.
Direct Access
Alternatively, if a straightforward web scraping approach does not work, the customer can provide Raffle Support the needed credentials to a supported integration in order to directly access and scrape the contents of a knowledge base.
Incomplete Scrape
If an article is not included in an index, try the following steps:
- Verify if the affected article has the noindex, nofollow meta tag
- By default, Raffle obeys the noindex, nofollow rule and automatically ignores articles with this tag
- Check if the page is included in the sitemap (e.g.
website.com/sitemaporwebsite.com/sitemap.xml)- An updated sitemap that lists all pages in the website is also used by the Raffle scraper to find pages that may not be linked from other pages
- Refer to Inclusions to manually add pages in the scrape
- Provide a list of articles to be included in the scrape to Raffle Support
Sync Status
The sync status displays an overview of the latest sync dates and statuses of available indexes, including those that may require attention and further adjustments.
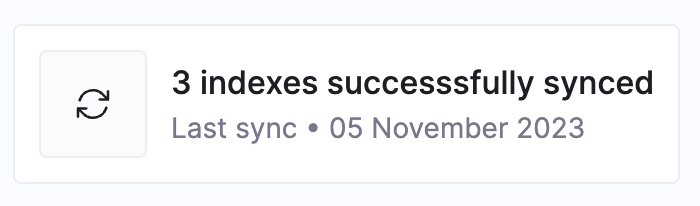
Sync Status Overview
Add Indexes
Contact Raffle Support to add new indexes. For a list of supported integrations, refer to Integrations.
Add New Index
View Indexes
View scraped indexes and underlying scraped articles.
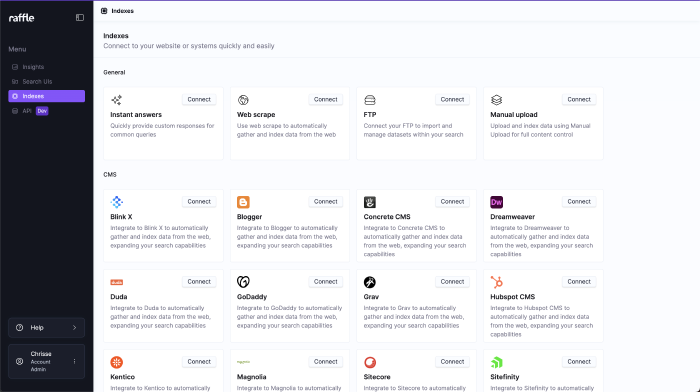
View Indexes (Start Page)
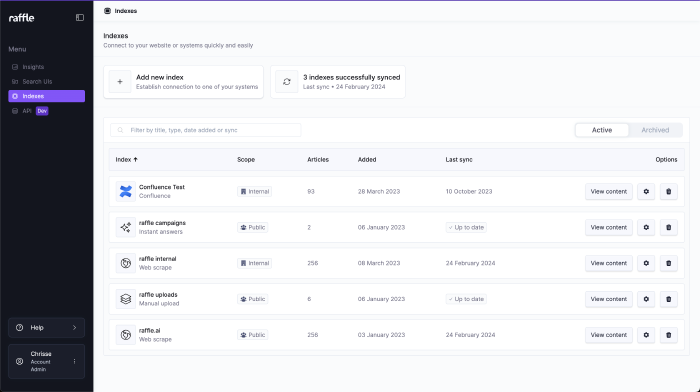
View Indexes (Filled List)
Filter
Filter indexes by title, type or date.
Steps
- Go to Indexes
- Type a search phrase on the search bar
- Press ENTER
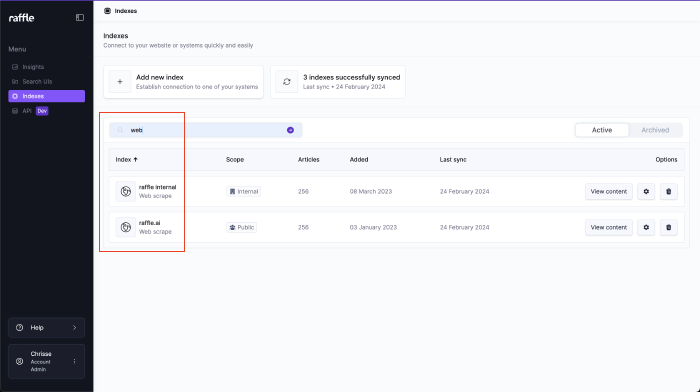
Filter Indexes
Sort
Sort items in ascending or descending order.
Steps
- Go to Indexes
- Click on a column title to sort a column
- Click the column title again to toggle between ascending, descending or no particular order
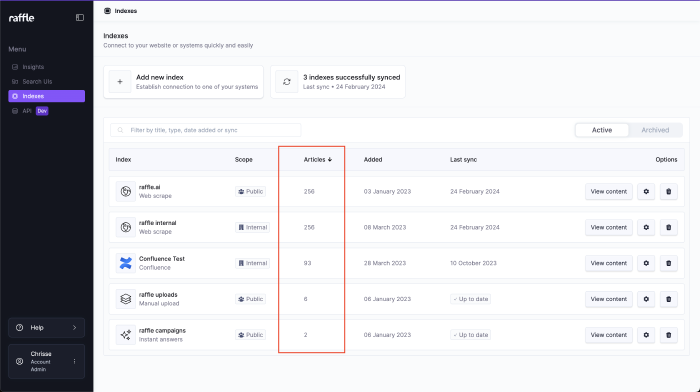
Sort Indexes
List
View scraped articles within an index.
Steps
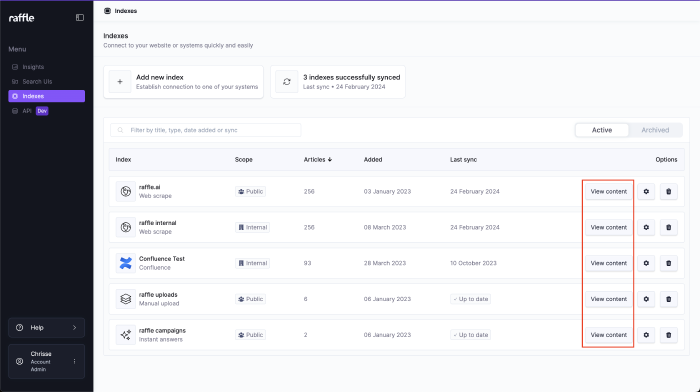
View Scraped Articles
Search
Search for articles within an index based on the whole or partial title or URL. Pagination and the total number of search hits are displayed at the bottom of the table.
Steps
- Go to Indexes
- Click VIEW CONTENT or click the index name
- Type full or partial article title or URL in the search bar
- Press ENTER
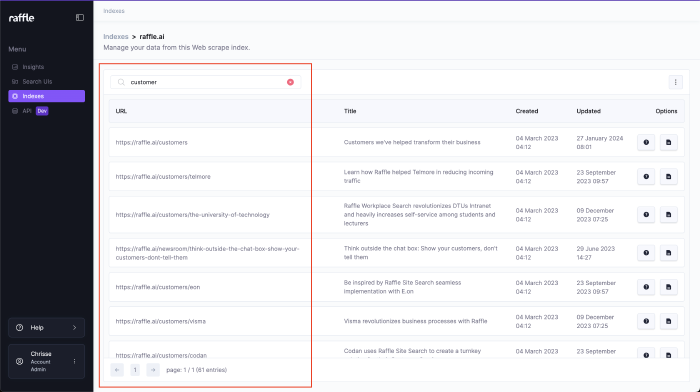
Search in Scraped Articles
Preview
Read and inspect the contents of a scraped article.
Steps
- Go to Indexes
- Click VIEW CONTENT or click the index name
- Click the paper icon to view the contents of a scraped article
- Click OPEN ORIGINAL to open the original article in a new tab
- Click X to close the preview
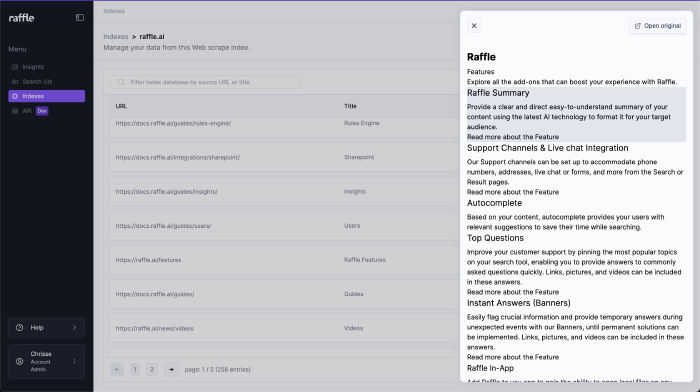
View Scraped Content
Manage Indexes
Manage various types of indexes. For a list of supported integrations, refer to Integrations.
Field Guide:
- Index Title: set the label of the index
- Entrypoint URLs: starting path to be visited by the Raffle scraper e.g
https://www.website.com/orhttps://website.com/ - Allowed Domain: domain (or subdomain) of a website e.g.
www.website.comorsubdomain.website.com(nohttps://or any (/)) - Included URLs: set of pages to be visited, followed and indexed as part of the scrape e.g.
^https://www.website.com/.*$(includes all pages in the website) - Excluded URLs: set of pages to be ignored and excluded from the scrape e.g.
^https://www.website.com/en.*$(scrapes all pages except those under/en)
Ensure that correct regular expressions rules are followed, and all required fields are duly filled out.
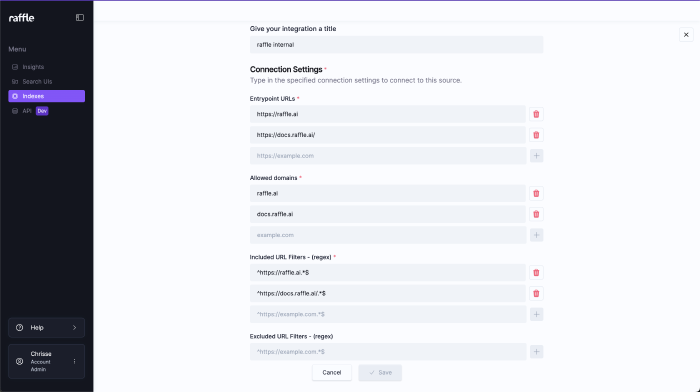
Customize Index Settings
Renaming
By default, indexes are named according to the path of the index e.g. full URL for a web scrape. This and other details can be configured as follows:
Steps
- Go to Indexes
- Click the gear icon to view the index settings
- Set the index title
- Click SAVE

Rename an Index
Inclusions
Raffle locates and scrapes published and searchable articles within a provided index. To manually include URLs:
Steps
- Go to Indexes
- Click the gear icon to view the index settings
- Add domains or subdomains to include under ALLOWED DOMAINS
- The scrape only indexes pages within the allowed domains
- Add URLs to include under INCLUDED URL FILTERS - (REGEX)
- Ensure that regex rules are followed, refer to the textfield placeholder for reference
- Click the plus icon to add an entry
- OPTIONAL: Click the delete icon to remove an entry
- Click SAVE

Manually Include Articles
Alternatively, provide a list of articles to include to Raffle Support.
Exclusions
Raffle locates and scrapes published and searchable articles within a provided index. To manually exclude URLs:
Steps
- Go to Indexes
- Click the gear icon to view the index settings
- Add URLs to exclude under the field EXCLUDED URL FILTERS - (REGEX)
- Ensure that regex rules are followed, refer to the textfield placeholder for reference
- Click the plus icon to add an entry
- OPTIONAL: Click the delete icon to remove an entry
- Click SAVE

Manually Exclude Articles
Alternatively, provide a list of articles to exclude to Raffle Support.
Rules Engine
Boost articles with specific keywords (using words, phrases, questions or suggestions).
Alternatively, provide a list of articles (include search words and target URL) to be boosted to Raffle Support.
Steps
- Go to Indexes
- Click VIEW CONTENT
- Click the question icon to launch the questions dialog
- Click ADD QUESTION to add a search term (one phrase per line)
- Add as many search words or phrases as possible, relevant to the scraped content
- Add the title of the article as a question, for further boosting
- OPTIONAL: Click the delete icon to remove a search term from the list
- Click SAVE
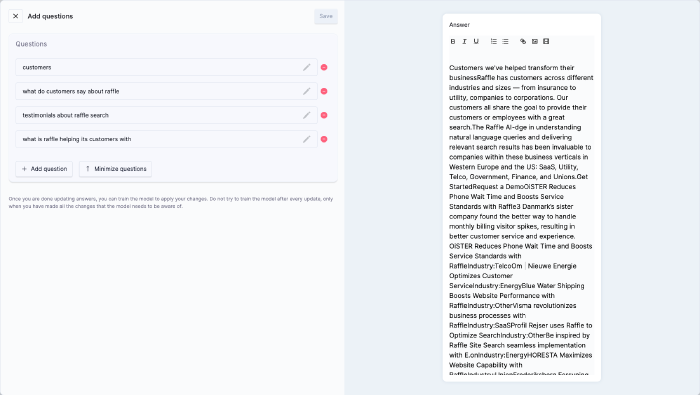
Boost Articles with Search Phrases
Archive Indexes
Active indexes can be archived for a period of time before permanently deleted.
Steps
- Go to Indexes
- Click the delete icon to archive an index
- Click CONFIRM
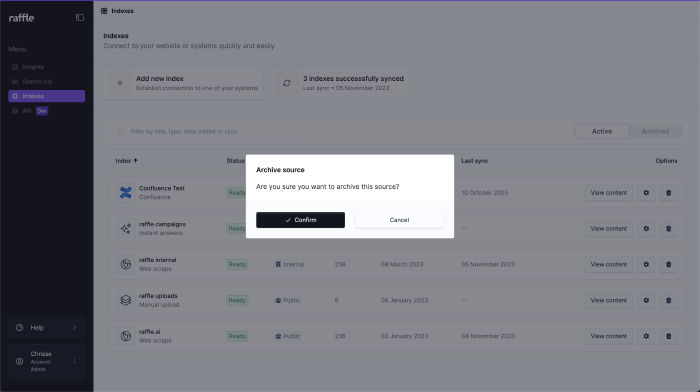
Archive an Index
Restore Indexes
Archived indexes can be restored or permanently deleted under the ARCHIVED tab.
Steps
- Click the restore icon to restore an index
- OPTIONAL: Click the delete icon to permanently delete an index
- Click CONFIRM
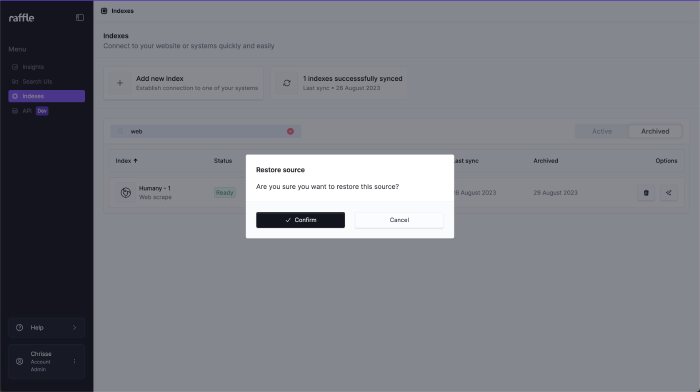
Restore an Index