SharePoint via API
Introduction
This document describes the process of building a search solution for SharePoint utilizing the Raffle API. The solution extracts pages and documents from SharePoint sites using the SharePoint REST API and adds these resources to the Raffle Search Engine, to achieve great search capabilities for the SharePoint content. By also fetching access control and adding to the Raffle search index, the search results are filtered to ensure that users only see what they have permission to see.
High-level Data Pipeline
The system is built around SharePoint as the data source, Raffle Search as the search engine, and Active Directory for user access control. The solution also utilizes either Azure Functions or a VM-based cron job for data synchronization and orchestration.
The image below is providing an end-to-end pipeline, from fetching and adding the content, building the relevant indexes and build the search application using the Raffle Search API:gimlet

To summarize, the overall steps needed to build a search solution for SharePoint based on Raffle Search API are as follows:
- Extract the pages and documents from SharePoint as well as the access control information for these items.
- Convert the content of these documents into json.
- Set up an index in Raffle with the relevant structures and fields to store the information about the resources and their permission data.
- Add the data to the index and make sure the index is updated when either SharePoint resources or access control information is changed.
- Orchestrate and run the system - either as a simple service in Azure, a cron job on a VM, or something similar. Decide when to update the index.
- Build the actual search application for SharePoint, to let the user type in a search query and view the results of the search. The search should be parameterized with information about the current user, so the search results can be filtered accordingly.
The remainder of this document will go into the details of the above list. However, it’s important to mention that this document is by no means exhaustive and should not be treated as a software specification, but more an overview of the steps to complete the solution.
Extracting Data from SharePoint
In this section we will go through the steps of getting data out of SharePoint.
Using SharePoint REST API
The SharePoint REST API is utilized to retrieve pages and documents from SharePoint sites. The REST API provides endpoints to fetch site contents, list data, and other resources that are useful for our search solution. Data is received in various formats. For example, .aspx files are returned as xml, but pdf, docx, txt, etc are returned in their respective native format. This means that the files will have to be converted to json before they can be added to the Raffle search index.
Authentication
In SharePoint, the authentication can be done by passing in a Client id and a Client Secret (there are also several other options) to get an access token. With that access token, the SharePoint REST API can be used to fetch the data (pages or documents).
SharePoint API
It‘s out of scope to go into details about how to use the SharePoint REST API, but the following resources are useful for getting to understand the SharePoint REST API in more detail:
- https://learn.microsoft.com/en-us/sharepoint/dev/sp-add-ins/get-to-know-the-sharepoint-rest-service?tabs=csom
- https://global-sharepoint.com/sharepoint-online/in-4-steps-access-sharepoint-online-data-using-postman-tool/#google_vignette
In Raffle, we have already implemented a general connector to SharePoint (which is part of the standard tool box), so we can certainly assist in getting the work started.
Access Control Information
An important aspect of the solution is to filter the results from the search engine based on what the user is allowed to see. In order to achieve this, the necessary access control information must be extracted for the SharePoint resources, which then can be indexed alongside the resource data in Raffle Search. This enables the search solution to filter search results based on user access permissions at runtime.
Access control information for a given page or document can be fetched from SharePoint using the roleassignments endpoint. You can read more about roleassignments endpoint and how to use it here:
We recommend not to apply the access control information based on the individual user, but keep it at the group level in order to handle the permissions in a more high level manner. It is assumed that most access information is added to groups instead of individual users and if not, it should be changed accordingly.
Once the access information is fetched, it should be added to a field on the documents being indexed.
Data Indexing in Raffle Search
Preparing Data
Once the data and access control information is extracted from SharePoint / AD, it needs to be prepared appropriately for Raffle Search. This involves creating JSON documents that are compliant with Raffle Search’s schema requirements.
We recommend checking the Raffle API documentation for more details, but essentially, it has to be configured to control how the different types of content should be searchable. For example, the body text of the document should be handled by vector-search and the access control information can be simple fields (e.g. strings) that are handled by the Solr compatible filtering.
Following is a link to the Raffle API documentation (still being updated):
https://cdn.raffle.ai/apidocs/index.html
Indexing Data
After adding the content, the data is then indexed in Raffle Search. This involves sending HTTP PUT requests to the appropriate Raffle Search endpoints. Each JSON document (representing a SharePoint resource) is sent separately for indexing.
Building the Search Bar in SharePoint
Implementing SharePoint Page Customizer Application
The search bar is embedded directly into SharePoint using a SharePoint Page Customizer App. This allows users to initiate searches directly from within SharePoint and receive results filtered according to their access permissions.
It will utilize the Raffle Search API and can be done in many different ways. Essentially, once deployed to SharePoint it could look something like this (Raffle’s own search bar):
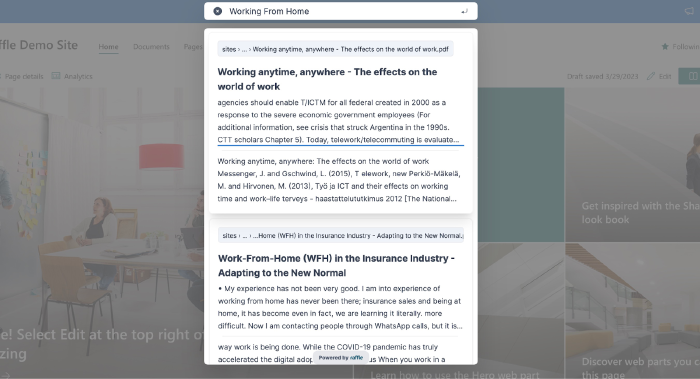
But since it will be based on the API, it can be tailored to look exactly as desired. The important thing is that the information about the currently logged in user (i.e. the group or groups he or she belongs to) is passed to the Search API so the resulting answer-list can be filtered accordingly.
Information about the currently logged in user can be fetched from the currentuser endpoint. You can read more about that here:
To get the information about all groups the user is part of, transitively, you can use the transitiveMemberOf endpoint within the Microsoft Graph API:
In general, the Microsoft Graph API allows you to interact with a wide range of AD and security related tasks, including getting information about a given user and the groups he or she belongs to.
Hosting the Solution
Once the proper structures have been defined and documents can be added, the solution needs to be run in some kind of environment. Ideally, the search index is updated every time either data or access control information is changed. That can be a bit tricky to get set up. Another, less ambitious approach is to run the update on a schedule basis, e.g. once every hour.
Using Azure Functions or VM-based Cron Jobs
Data and index updates can be orchestrated using either Azure Functions or a VM-based cron job. The choice largely depends on your resource availability and cost considerations.
Azure Functions would be an ideal choice if you prefer a serverless architecture. You can create a function to handle data extraction, structuring, and indexing processes, and set up a timer trigger to execute this function periodically.
On the other hand, if you already have a VM set up and prefer not to add Azure Functions to your tech stack, a cron job running on the VM could handle these tasks. The cron job can be set up to run a script at regular intervals to perform the necessary data synchronization and indexing operations.
Overall Estimation
It’s difficult to say exactly how long time putting such a solution together will take since it depends a lot on the knowledge of the different technologies involved (e.g. working with the SharePoint APIs, setting up services or scheduled job, building web widgets and SharePoint applications), but assuming some base-knowledge of the above, it should be possible to complete in roughly 3-6 months (depending on how advanced the solution should be in terms of hosting, synchronization, granularity of access control information etc).
Conclusion
Building a search solution for SharePoint using Raffle Search involves several components, including SharePoint itself, Raffle Search for data indexing, and Active Directory for user access control. Admittedly, these steps are far from trivial, but the process is quite similar to how it would be done using other Search frameworks (e.g. ElasticSearch), here you just get the true benefits and advantages of using Raffle’s powerful AI-based vector search engine and not just Solr (keyword search).
The Raffle Search API is built and tailored for these types of projects, so even though there are complex steps involved, the work should be fairly straightforward.